上期我们将前6个挑战及其建议的解决方法一一列举,这期我们一起来解决剩余的6个问题:
痛点 7: 回答不全面
部分答案虽然不算错误,但缺少了一些细节,这些细节虽然在上下文中已有所体现,却未被完全展现出来。举个例子,若有人询问“文档 A、B 和 C 主要讨论了哪些方面?”针对每个文档单独提问可能更为合适,这样能确保得到更加详尽的回答。
1.查询变换的技巧
在自动化知识获取(RAG)过程中,对比较类问题的处理往往不尽人意。一个有效提升 RAG 处理能力的策略是增设一个查询理解层,即在实际检索知识库之前进行一系列的查询变换。具体来说,我们有以下四种变换方式:
- 路由:在不改变原始查询的基础上,识别并定向到相关的工具子集,并将这些工具确定为处理该查询的首选。
- 查询改写:在保留选定工具的同时,通过多种方式重构查询语句,以便跨相同的工具集进行应用。
- 细分问题:将原查询拆解为若干个更小的问题,每个问题都针对特定的工具进行定向,这些工具是根据它们的元数据来选定的。
- ReAct 代理工具选择:根据原始查询判断最适用的工具,并为在该工具上运行而特别构造的查询。
以下是如何利用 HyDE(假设性文档嵌入)技术,一个查询改写的示例。首先根据自然语言查询生成一个假定的文档/答案,然后使用这个假设性文档来进行嵌入查询,而非直接使用原始查询。
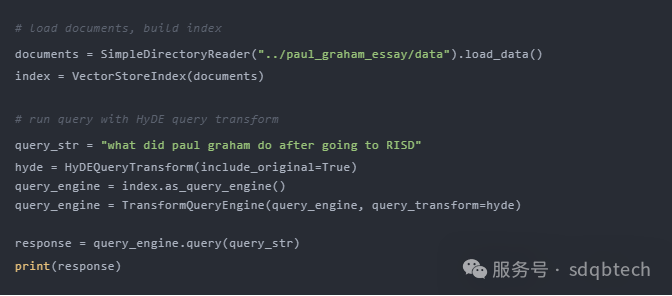
请访问 LlamaIndex 的查询变换指南,以获取更多详细信息。
https://docs.llamaindex.ai/en/stable/examples/query_transformations/query_transform_cookbook/同时,不要错过 Iulia Brezeanu 的精彩文章提升 RAG 性能的高级查询变换技巧,其中详细介绍了查询变换技术。
https://towardsdatascience.com/advanced-query-transformations-to-improve-rag-11adca9b19d1以上所述问题均源自相关研究论文。现在,我们来看看在 RAG 开发中常见的另外五个问题及其解决方案的探讨。
痛点 8:数据摄入的可扩展性问题
在 RAG 系统中,数据摄入的可扩展性问题指的是系统在有效管理和处理大规模数据时面临的挑战,这可能导致性能瓶颈甚至系统故障。这类问题可能会造成数据摄入时间过长、系统过载、数据质量下降以及可用性受限等现象。
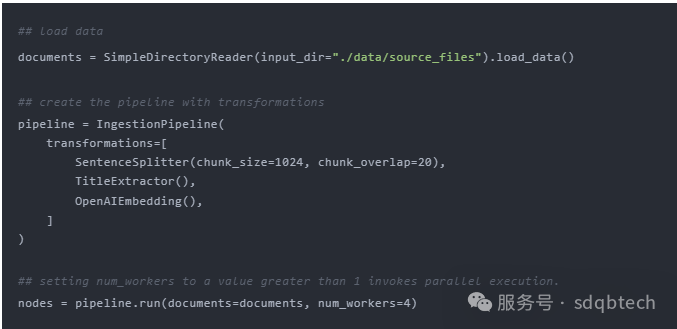
1.加速文档处理:并行摄取技术
LlamaIndex 引入了文档处理的并行技术,通过这项创新功能,文档处理速度最高可提速至 15 倍。参照以下示例代码,即可快速了解如何创建 IngestionPipeline 并设置 num_workers 参数,以启动并行处理机制。想要深入了解,不妨访问 LlamaIndex 提供的详细教程。
痛点 9:结构化数据的问答
解读用户的查询并准确检索到所需的结构化数据是一项挑战,尤其是当面对复杂或模糊的查询请求时。这一挑战由于文本到 SQL 的转换不够灵活,以及当前大语言模型在处理这些任务上的局限性而更加复杂。
LlamaIndex 提出了两种解决方案来应对这一挑战。
1.链式思维表格包
基于 Wang 等人创新的“链式表格”论文,ChainOfTablePack 是一种特别设计的工具包。这种方法通过“链式思维”与表格的转换及展示相结合,允许以一套限定的操作逐步变化表格,并在每一步中将变化后的表格展示给大语言模型。这种方式特别适合处理包含多重信息的复杂表格单元问题,通过逐步精确地切割和解析数据,直至找到所需的数据子集,显著提高了对表格数据的查询效率。欲了解如何利用 ChainOfTablePack 来优化您的结构化数据查询,详见 LlamaIndex 提供的实践指南。
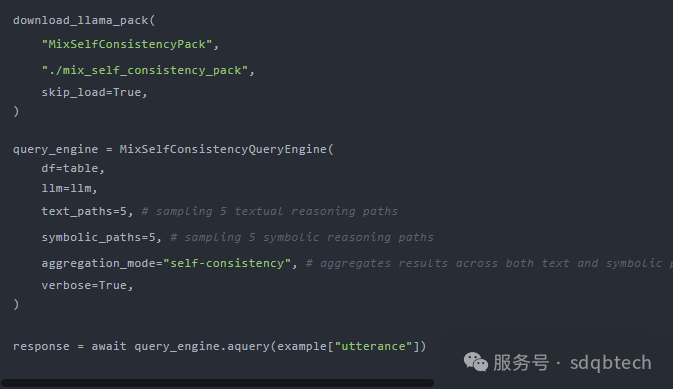
2.混合自洽查询引擎包
大语言模型(LLM)能以两种主要方式对表格数据进行推理:
- 通过直接询问进行文本推理
- 通过程序合成(如 Python、SQL 等)进行符号推理
依据 Liu 等人的研究《重新思考大语言模型如何理解表格数据》,LlamaIndex 创新性地开发了 MixSelfConsistencyQueryEngine。该引擎结合了文本与符号推理的结果,并通过自洽机制(即,多数投票法)实现了最先进(State of the Art,SoTA)的性能表现。以下是一个示例代码片段。欲了解更多细节,可以查阅 LlamaIndex 的完整笔记本。
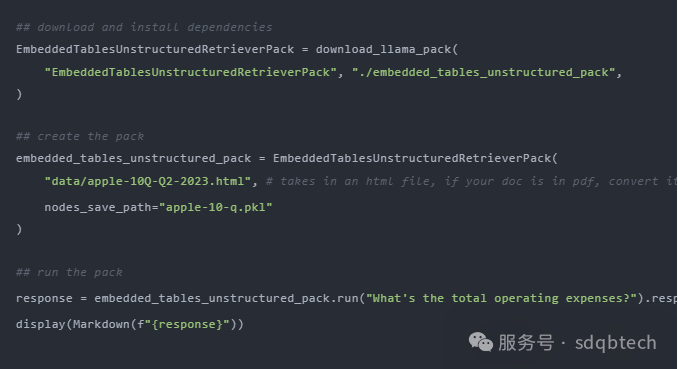
痛点 10:从复杂 PDF 文档提取数据 在从复杂 PDF 文档,如嵌入表格的文档中提取数据进行问答时,传统的检索方法往往无法达到目的。您需要一个更高效的方法来处理这种复杂的 PDF 数据提取需求。 1.嵌入式表格检索技术 LlamaIndex 提出了一种解决方案,名为 EmbeddedTablesUnstructuredRetrieverPack。这个 LlamaPack 利用 Unstructured.io 解析 HTML 文档中的嵌入式表格,创建节点图,并通过递归检索根据用户提出的问题来索引和检索表格。 请注意,此方案需要将 PDF 文档作为输入。如果您手头上的是 PDF 文件,可以使用 pdf2htmlEX 工具,将 PDF 转换为 HTML 格式,同时保留原文的文字和格式。以下是如何下载、初始化及运行 EmbeddedTablesUnstructuredRetrieverPack 的示例代码片段。
痛点 11:备用模型策略
在使用大语言模型过程中,您可能会担心模型可能会遇到问题,比如遇到 OpenAI 模型的访问频率限制错误。这时候,您就需要一个或多个备用模型作为后备,以防主模型出现故障。
两种建议的解决方案:
1.Neutrino 路由器
Neutrino 路由器是一个能够处理你提出的各种查询的大语言模型集群。它利用一个先进的预测模型,智能地选择最适合你问题的大语言模型,既提升了处理效果,也节约了成本并减少了等待时间。目前,Neutrino 支持多达十几种不同的模型,如果你有需要新增的模型,可以随时联系他们的客服团队。
你可以在 Neutrino 的用户面板中自由选择你喜欢的模型来创建一个专属路由器,或者直接使用包含所有支持模型的“默认”路由器。
LlamaIndex 已经通过其llms模块中的Neutrino类,加入了对 Neutrino 的支持。详细信息请参见以下代码示例,更多细节可查阅Neutrino AI 页面。
2.OpenRouter
OpenRouter提供了一个一站式的 API 接口,使你能够接入任何大语言模型。它不仅能帮你找到市场上任一模型的最低价格,还能在你首选的服务提供商遇到问题时,自动切换到其他选项。按照OpenRouter 的官方文档所述,选择 OpenRouter 的主要优势包括:
享受价格竞争带来的好处。OpenRouter 会在众多服务提供商中为每个模型寻找最低价格。你还可以允许用户通过OAuth PKCE自行支付模型费用。
统一的 API 接口。在模型或服务提供商之间切换时,无需修改代码。
使用频率最高的模型品质最优。通过查看模型的使用频率,很快你还能根据使用目的来比较模型性能。
LlamaIndex 通过其llms模块中的OpenRouter类,实现了对 OpenRouter 的支持。
痛点 12:大语言模型的安全性
在设计和开发 AI 系统时,如何有效防止恶意输入、确保输出安全、保护敏感信息不被泄露等问题,都是每位 AI 设计师和开发者需要面对的重要挑战。
1.Llama Guard:保护大语言模型的新工具
借鉴 7-B Llama 2 的技术,Llama Guard 旨在通过评估输入(例如分析提问的内容)和输出(即对回答的分类)来帮助大语言模型 (LLMs) 鉴别内容是否安全。它本身也使用了大语言模型技术,能够判断某个问题或回答是否安全,若发现不安全的内容,还会详细列出违反的具体规则。
LlamaIndex 现提供 LlamaGuardModeratorPack 工具包,开发人员只需简单一行代码,就能在下载并初始化该工具包后,轻松调用 Llama Guard 来对大语言模型的输入和输出进行监督。