研究在开发检索增强生成(RAG)系统时遇到的 12 个主要难题(包括原论文中的 7 个和额外发现的 5 个),并提出了针对每个难题的解决策略。以下图表改编自原始论文《开发检索增强生成系统时的七个常见挑战》中的图表
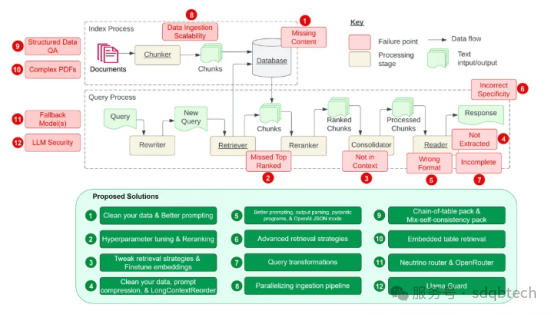
图示改编自《开发检索增强生成系统时的七个常见挑战》。
通过将这 12 个挑战及其建议的解决方法并列在一张表中,现在可以更直观地理解这些问题及其对策:
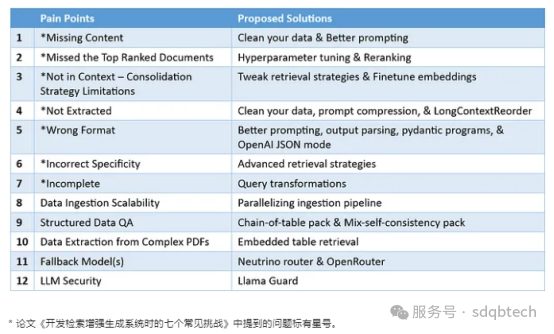
痛点 1:缺失内容
当实际答案不在知识库中时,RAG 系统可能会提供一个貌似合理但实际错误的答案,而不是直接表明自己无法给出答案。这种情况下,用户可能会因为接收到误导性信息而感到困惑和挫败。
针对此问题,我们提出两种解决策略:
1.数据清洗的重要性
俗话说,“差料出差货”。如果你的原始数据充满错误,如信息自相矛盾,那么无论你如何搭建你的 RAG 处理流程,都无法将输入的杂乱无章转化为有价值的信息。这一解决策略不仅适用于本文讨论的这一问题,也适用于所有提及的问题。高质量的数据是构建任何有效 RAG 流程的基础条件。
2.精心设计的prompt有助于提高准确性
当系统因为缺少知识库中的信息而可能给出看似合理但实际错误的回答时,一个好的提示可以大有裨益。例如,通过设置提示:“如果你对答案不确定,就告诉我你不知道”,可以鼓励模型承认其局限性,并更透明地表达不确定性。虽然无法保证百分百的准确率,但在数据清洗之后,设计恰当的prompt是提高回答质量的有效手段之一。
痛点 2:关键文档被遗漏
有时候,重要的文档可能不会出现在系统返回的最顶端结果中,导致正确的答案被忽略,系统未能提供准确的反馈。正如一篇研究所暗示的那样:“答案虽然在文档中,但因为排名不够高而未能展现给用户”。
我想到了两种可能的解决方法:
1.通过调整chunk_size和similarity_top_k参数优化检索效果
chunk_size 和 similarity_top_k 这两个参数关键影响了 RAG 模型在数据检索过程中的效率和准确性。适当调整这些参数,可以在计算效率和信息检索质量之间找到更好的平衡点。关于如何调整这些超参数,我们在先前的文章通过 LlamaIndex 实现超参数自动调整中有详细讨论,并提供了示例代码。

函数objective_function_semantic_similarity的定义如下,它利用 param_dict 中的参数 chunk_size 和 top_k 以及它们推荐的值进行了说明:
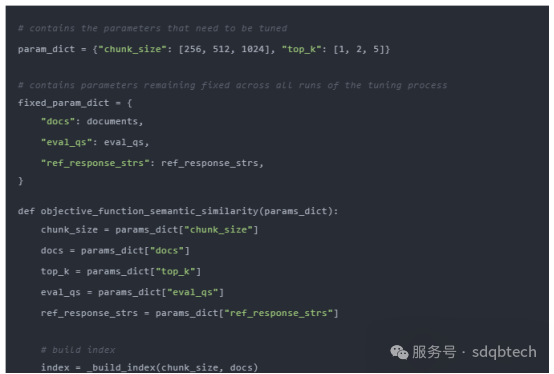
更多细节可以参考 LlamaIndex 提供的关于对 RAG 进行超参数优化的完整教程。
https://docs.llamaindex.ai/en/stable/examples/param_optimizer/param_optimizer
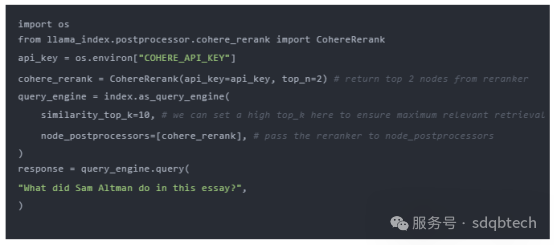
2.检索结果的优化排序(reranker)
在结果送达大语言模型 (LLM) 前对它们进行优化排序,极大地提升了 RAG 技术的效能。LlamaIndex 的示例笔记*清晰展现了优化排序的前后差异:
- 未采用优化排序器,直接提取前两个节点,导致的检索不精确。
- 先提取前十个节点,再用 CohereRerank 进行优化排序,精选出最相关的两个节点。
另外,通过各种嵌入技术和排序器,我们可以对检索性能进行评估和提升,详见 提升 RAG 性能:挑选最优的嵌入技术和排序模型* 由 Ravi Theja 撰写。
更进一步,定制化的排序器经过微调后能够实现更优的检索性能,具体实施方法请参阅通过微调 Cohere 排序器与 LlamaIndex 提升检索效果*,也是由 Ravi Theja 介绍。
痛点 3:文档整合限制 —— 超出上下文
论文指出:“答案所在的文档虽从数据库中检索出来,但并未包含在生成答案的上下文中。”这种情况通常发生在数据库返回众多文档,并需通过一个整合过程来选取答案的场景。
为了解决上述问题,除了增加排序器和对其进行微调外,我们还可以尝试以下建议的解决方案:
1.调整检索策略
LlamaIndex 提供了多种从基础到高级的检索策略,以确保我们在 RAG 流程中能够准确地检索信息。详细的检索策略列表请参见 检索器指南,其中包括:
- 基础检索:针对每个索引执行
- 高级检索与搜索
- 自动检索
- 知识图谱检索
- 组合/层级检索
等等!
这一系列的策略为我们提供了灵活性和多样性,以适应不同的检索需求和场景,从而提高检索的精确度和有效性。
https://docs.llamaindex.ai/en/stable/module_guides/querying/retriever/retrievers
2.微调嵌入技术
如果您在使用开源嵌入模型,对其进行微调是提高检索准确度的有效手段。LlamaIndex 提供了一份详细的微调指南(查看微调指南),展示了如何微调开源嵌入模型,并证明了这一过程能够在多个评估指标上持续提升性能。
https://docs.llamaindex.ai/en/stable/examples/finetuning/embeddings/finetune_embedding
下方是一个示例代码片段,介绍了如何创建微调引擎、执行微调过程以及获取微调后的模型:
痛点 4:提取困难
当系统面对信息过载时,往往难以准确提取出所需的答案,关键信息的遗漏降低了回答的质量。研究表明,这种情况通常发生在上下文中存在过多干扰或矛盾信息时。
以下是针对这一问题提出的三种解决策略:
1.数据清洗
数据的质量直接影响信息提取的效果,这个痛点再次凸显了优质数据的重要性。在指责你的 RAG 系统之前,确保你已经投入足够的精力去清洗数据。
2.提示信息压缩
长上下文场景下的提示信息压缩技术首次由 LongLLMLingua 研究项目提出,并已在 LlamaIndex 中得到应用。现在,我们可以将 LongLLMLingua 作为节点后处理器来实施,这一步骤会在检索后对上下文进行压缩,然后再送入大语言模型处理。
更多详细信息,请参阅有关 LongLLMLingua 的 完整笔记本。
3.LongContextReorder(长内容优先排序)
一项研究 发现,当关键数据被放置在输入内容的开始或结尾时,往往能够获得最佳的性能表现。为了解决信息在输入中间部分“迷失”的问题,LongContextReorder 应运而生,它通过重新排序检索到的节点来优化处理,特别适用于需要处理大量顶级结果的情形。
想要了解更多详情,可以参考 LlamaIndex 提供的关于 LongContextReorder 的详细教程。
https://docs.llamaindex.ai/en/stable/examples/node_postprocessor/LongContextReorder
痛点 5:格式错误
当一个指令要求以特定格式(如表格或列表)提取信息而被大语言模型忽略时,提出了四种解决策略:
1.改进提示方法
可以采用以下策略来改进你的提示,解决这个问题:
- 明确说明指令。
- 简化请求并使用关键字。
- 提供示例。
- 采用迭代提示,提出后续问题。
2.输出解析
输出解析可以在以下方面帮助确保获得期望的输出:
- 为任何提示/查询提供格式化指令。
- 对大语言模型的输出进行“解析”。
LlamaIndex 支持与其他框架如 Guardrails 和 LangChain 提供的输出解析模块集成。
https://docs.llamaindex.ai/en/stable/module_guides/querying/structured_outputs/output_parser
3.Pydantic 程序简介
Pydantic 程序是一个多用途框架,能将输入的文本字符串转化成结构化的 Pydantic 对象。LlamaIndex 为我们提供了多种 Pydantic 程序:
- 文本自动完成 Pydantic 程序:通过结合使用文本自动完成的 API 和输出解析功能,这类程序能处理并将输入文本转换成用户定义的结构化对象。
- 函数调用 Pydantic 程序:这类程序接受文本输入,并依据用户的设定,通过调用大语言模型的函数 API,转换成特定的结构化对象。
- 预封装 Pydantic 程序:旨在将输入的文本转化为已预定义的结构化对象,简化用户操作。
4.OpenAI 的 JSON 应答模式
通过设置[response_format](https://platform.openai.com/docs/api-reference/chat/create#chat-create-response_format)为{“type””json_object”},我们可以启用OpenAI应答的JSON模式。这一模式限制模型只生成可以解析为有效 JSON 对象的字符串,虽然这强制了输出的格式,但并不针对某一特定模式进行验证。详细信息可参见 LlamaIndex 关于使用 OpenAI 的JSON 模式与函数调用进行数据提取的对比 的文档。
https://docs.llamaindex.ai/en/stable/examples/llm/openai_json_vs_function_calling
痛点 6:缺乏具体细节
有时候,回答可能不够详细或具体,可能需要进行多次追问才能得到清晰的解答。这些答案或许太泛泛,没有有效地满足用户的实际需求。
为此,我们需要采用更高级的检索策略来寻找解决方案。
1.进阶检索技巧
当你发现答案的详细程度没有达到预期时,通过优化检索策略可以显著提升信息获取的精确度。以下是几种能够有效缓解此类问题的高级检索技巧:
- 从小到大的信息聚合检索
- 基于句子窗口的检索
- 递归式检索方法
想要深入了解更多高级检索方法,请参阅我之前的文章如何通过高级检索 LlamaPacks 优化您的 RAG 流程,并利用 Lighthouz AI 进行性能基准测试,其中详细介绍了七种进阶检索技巧的 LlamaPacks。
https://docs.llamaindex.ai/en/stable/examples/retrievers/auto_merging_retriever
https://docs.llamaindex.ai/en/stable/examples/node_postprocessor/MetadataReplacementDemo
https://docs.llamaindex.ai/en/stable/examples/query_engine/pdf_tables/recursive_retriever