基于GPU视频编解码技术应用
GPU视频编解码是指使用图形处理单元(GPU)来加速视频的编码(压缩)和解码(解压)过程。由于GPU设计初衷是处理大量并行计算任务,尤其是图像和视频数据,它非常适合进行视频编解码工作。利用使用GPU进行视频编解码可以显著提高处理速度,减少延迟, 同时将视频编解码任务从CPU转移到GPU可以释放CPU资源,使CPU能够处理其他计算任务,从而优化整体系统性提升,这一趋势使得图像处理人员投身这方面的研究和部署自己的工程项目中。
这里做一下简单的科普:视频编解码的流程通常包括几个关键步骤,这些步骤共同确保视频内容可以被有效地解压缩、处理、再次压缩和存储转发,以及在需要时能被准确地显示。
1、首先需要从支持的监控Camera相机中获取RTSP原始视频流,国内主要的厂商有海康卫视和大华两家核心供应商,其Camera原始视频数据支持H264/H265/HEVC帧获取,这些帧中通常包含大量信息,包括音频和视频帧。因为图像工程师只关注视频流,往往忽视音频流数据处理,这里也不做过多介绍,视频帧包括成千上万的像素,每个像素包含颜色和亮度信息。原始视频数据通常非常大,需要压缩以便于传输和存储。这些帧信息的压缩通常在相机内部完成,通过网络传输的仅是H264/H265的信息,数据量非常小,比如1920×1080×3彩色帧压缩H264仅有1/4大小的数据量,甚至更小,这样非常容易在网络上进行传输和转存。
2、然后用户在获取RTSP的H264帧之后,在进行视频解码,解码是一个比较复杂的事情,其中核心的是编码器的选择,既可以使用低功耗的cpu解码,也可以使用gpu进行解码。视频解码是将压缩的视频数据转换可处理的视频格式的过程,这一过程相对于编码而言,速度较快。
3、然后对解码的视频进行处理,比如视频推理、视频融合、视频水印等,这部分是视频处理的重要一环。
4、视频编码是一个将视频处理过的数据二次在加工,加工之后的数据又变成新的H264/H265数据,相比于原始的数据流,该数据流是经过处理过数据流,其格式相同,数据量基本相近,二次加工的目的主要方便存储和在网络上进行传输。
5、压缩后的视频可以通过网络传输上以极小的网络带宽进行传播和播放。这里可能会用到视频推流技术,其技术就是将视频流显示是不同终端、不同设备上,方便内容分发和转发。
当然进行上述逻辑的除了必要的硬件编解码外,还需要ffmpeg和gstreamer工具支持,这里仅阐述ffmpeg的工具的支持,因为ffmpeg工具使用较为广泛,且易用性较好,代码易开发和公开资料较多。这里只做简单介绍,ffmpeg 是一个非常强大的开源多媒体框架,能够录制、转换和流化音频和视频。结合 GPU 使用 FFmpeg 可以显著提高视频处理的性能,对于开发人员是非常容易上手和开发部署的。
如果要让ffmpeg支持视频编解码,需要让ffmpeg支持cuda的编解码器,如下图所示:
window 系统+RTX3060+FFMPEG
基于其背景知识,我们构建自己的视频编解码框架,同时应用该流程到视频融合项目中:
首先FFMPEG+GPU使用h264_cuvid 进行视频的H264解码,将解码H264的数据转成yuv,然后再使用gpu的多线程技术将yuv转成rgb数据格式,这一过程称作视频的解码过程; 然后将解码的数据流进行各种处理,这里对获取的多路解码视频进行视频融合,视频融合的路数支持受限于RTX显卡的解码路数。然后在进行视频编码,视频编码仍然使用GPU的h264_nvenc 进行编码,编码的过程是将rgb格式的数据编码成yuv这里仍然使用GPU多核心进行处理,处理过程代码片段。
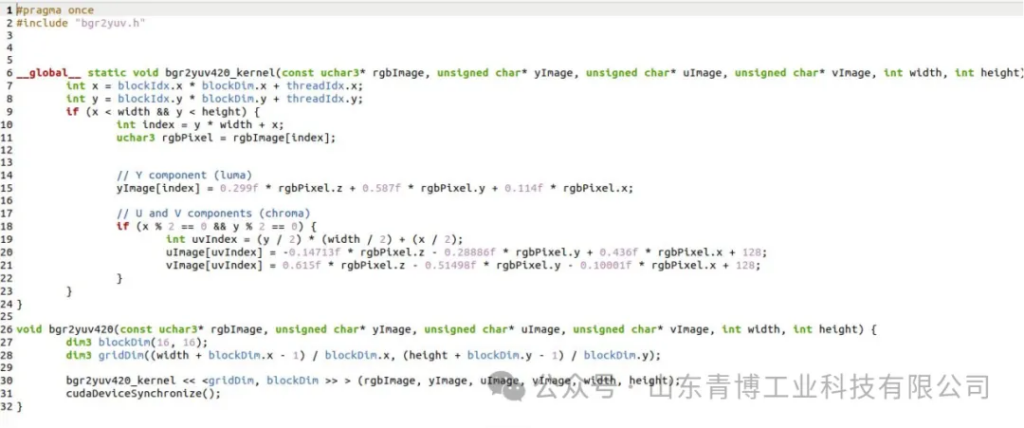
然后将yuv数据转成h264数据,这一过程称作视频编码过程,编码的主要目的和解码的目的基本一致,就是使用尽量小的带宽传递尽量多的数据,让数据在网络上进行传递。然后将h264数据推送到服务端,进行视频推流显示,推流显示以自建立RTServer为基础进行显示。
基于项目保密性问题,这里仅提供一组数据对比,对比cpu和gpu的真实解码视频帧率差异
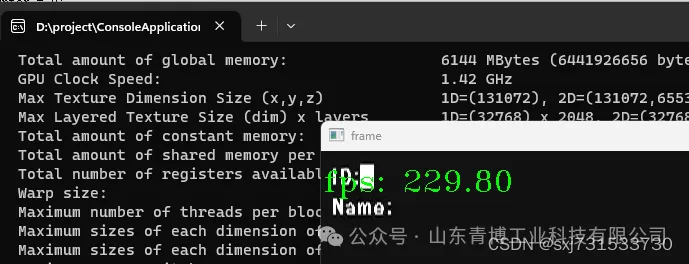
cpu的解码视频真实帧率
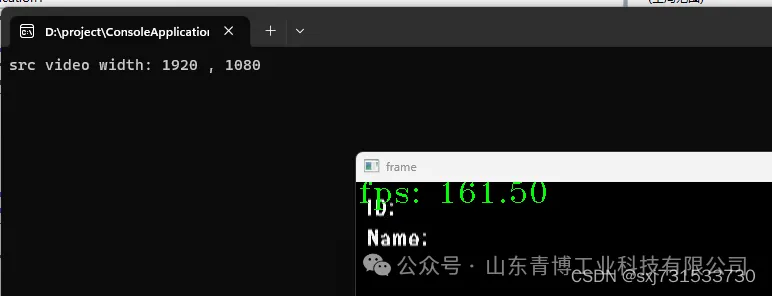
gpu解码视频的真实帧率